The Data
The London deployment generated over one million individual air quality readings across a 5 km² area of the city over three months. Analysis of this dataset is ongoing, but it is already revealing something important: urban air quality is far more complex, and far more variable, than the existing monitoring infrastructure allows us to see.
A dataset unlike any other
What makes the Local Air dataset unusual is not just its volume, but its character. Most air quality datasets are generated by fixed sensors at a small number of locations. They tell you what the air is like at those specific spots, averaged over time. The Local Air data is different. It was gathered by sensors moving continuously through the city, sampling the air at thousands of different locations across the deployment area.
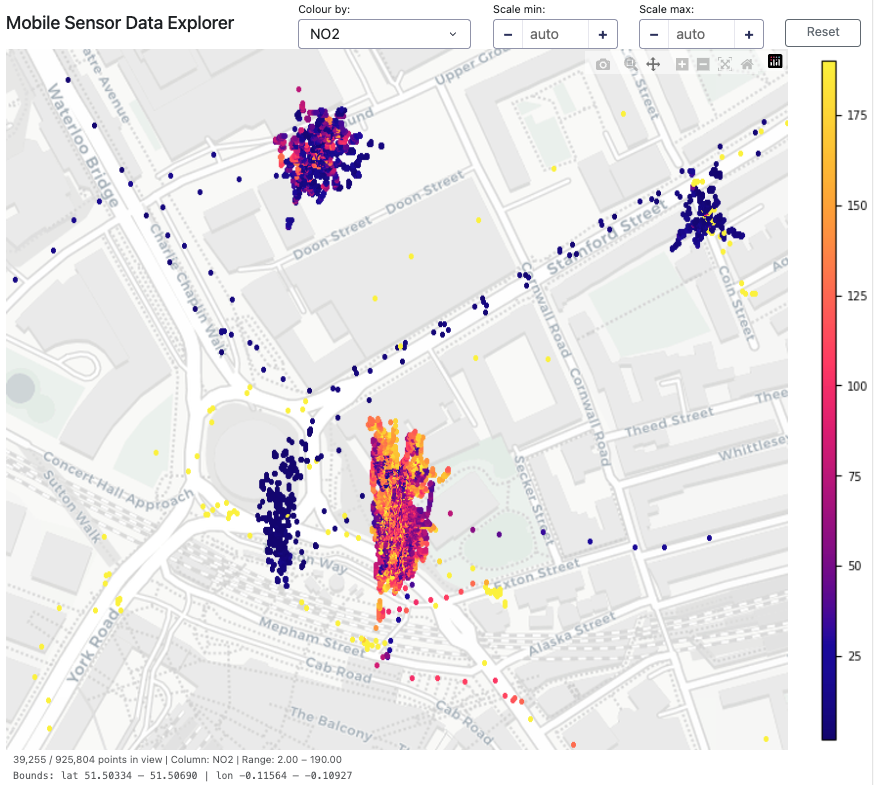
The result is a dataset that captures both the spatial and temporal variation of urban air quality in a way that has simply not been possible before. Air quality doesn't just vary from neighbourhood to neighbourhood, it varies from street to street, and from hour to hour. The Local Air data is beginning to show us just how much.
Correlations with static sensors
Despite the mobile nature of the sensors, the data shows clear and consistent correlations with readings from established static monitoring stations in the deployment area. This is an important validation: it confirms that the Local Air sensors are measuring real air quality signals, not noise, and that the mobile approach generates data that is comparable and complementary to conventional monitoring.
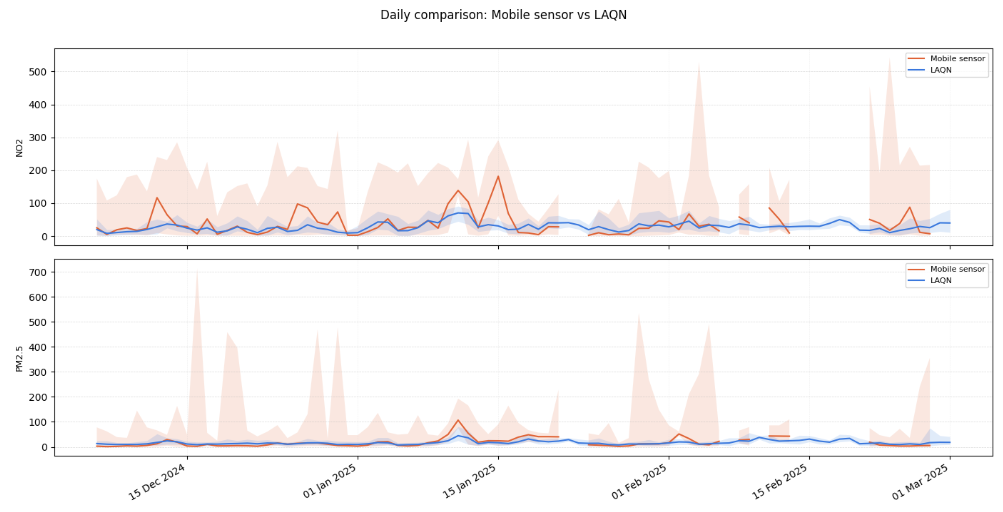
The complexity of urban air quality
One of the most striking early findings is just how much air quality varies across relatively short distances. Different parts of the deployment area show markedly different patterns of correlation with background pollution levels, suggesting that local sources of pollution (traffic junctions, bus stops, particular road types) are having a significant and highly localised effect on air quality, distinct from the city-wide background level.
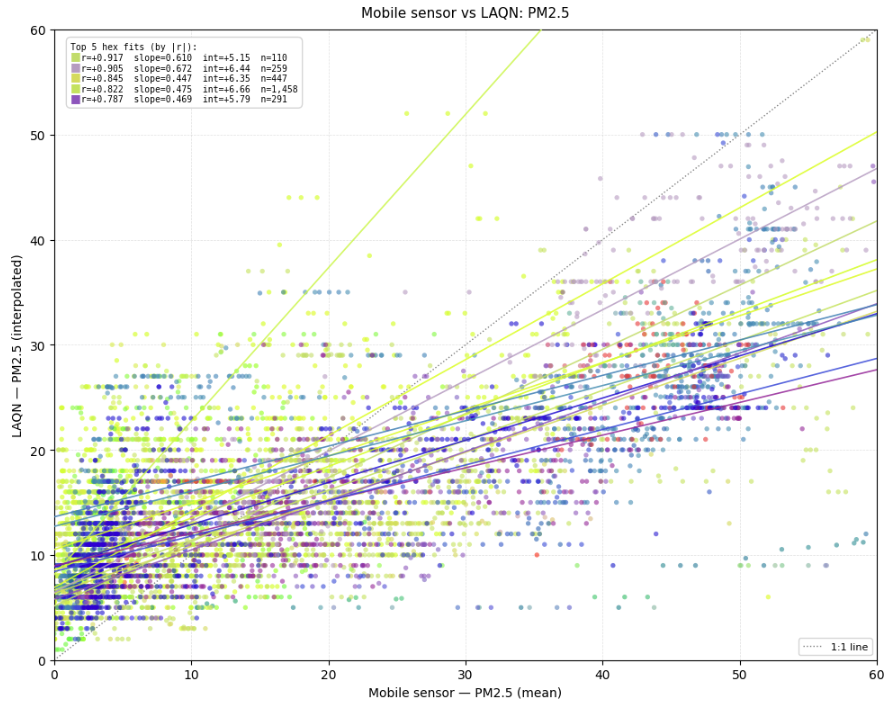
This is exactly the kind of insight that a fixed monitoring network, however well designed, cannot provide. Understanding these local patterns is essential for targeting interventions effectively, and for understanding the real-world impact of those interventions once they are in place.
Background vs. local sources
Early analysis is also beginning to disentangle the relative contributions of background pollution (pollution that drifts in from across the wider region) and locally generated sources, such as traffic on specific roads. This distinction matters enormously for policy: background pollution requires action at a regional or national level, whilst locally generated pollution can be addressed through targeted local interventions. The spatial granularity of the Local Air dataset is making this kind of source attribution analysis possible for the first time at this scale.
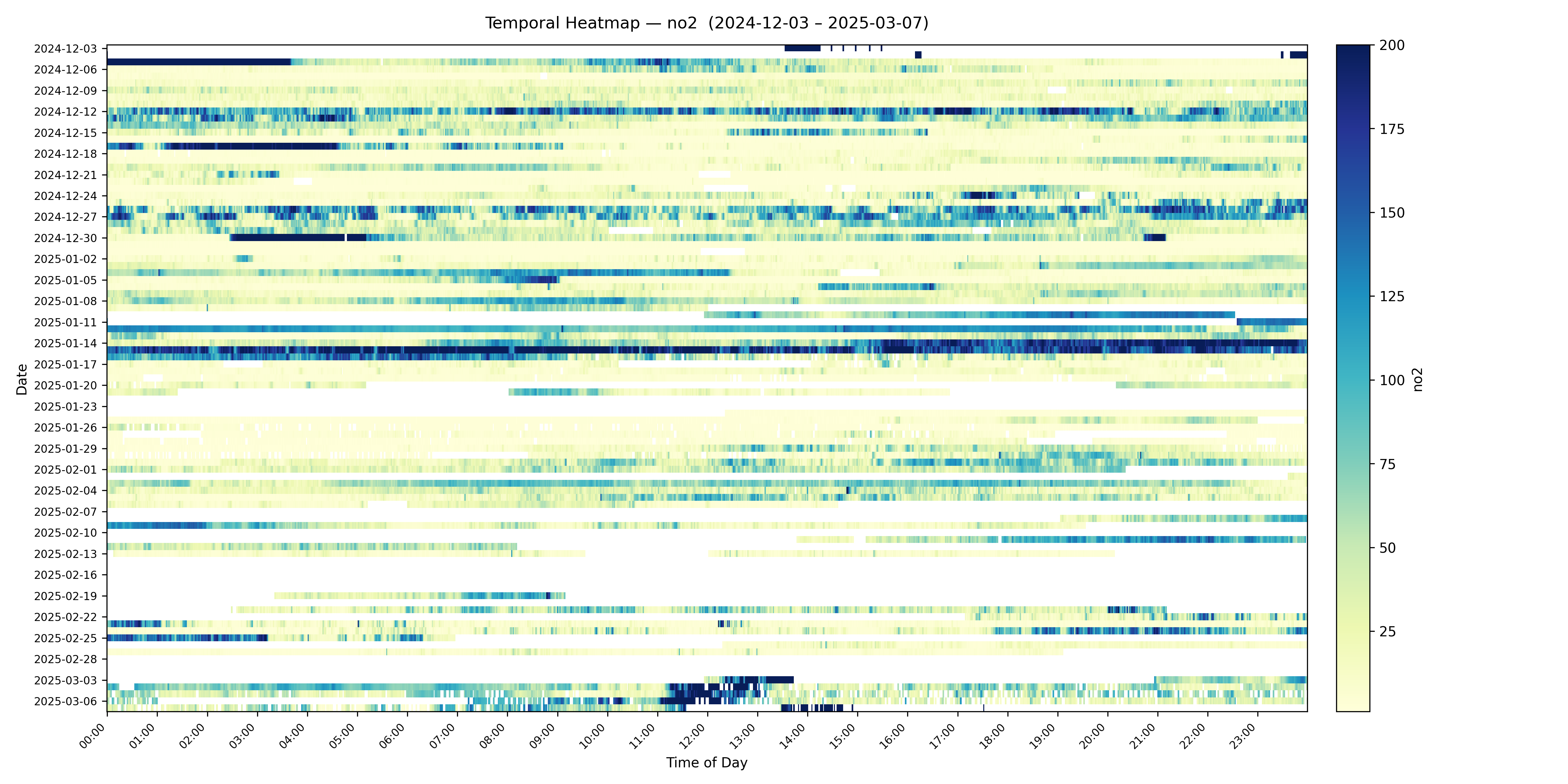
Fly-by calibration
One of the known limitations of low-cost sensors is drift. This a gradual change in sensor response over time that can reduce the accuracy of readings. The Local Air team aims toaddress this using a technique we call fly-by calibration.
As sensors move through the city, they periodically pass close to high-accuracy reference instruments (DEFRA monitoring stations, for example) as well as passing near to one another. Each of these proximity events is an opportunity to compare readings and correct for any drift that has developed. By building these corrections into the data processing pipeline automatically, it becomes possible to maintain the accuracy of the sensor network over time without physically retrieving and recalibrating each unit.
This is a novel approach that (to our kowledge) does not yet exist in the literature, and developing the algorithms to make it work is one of the key research contributions of the next phase of the project.
Model integration
The Local Air dataset is also being explored as a resource for validating and improving atmospheric and meteorological models of urban airflow. Bristol's distinctive topography (dominated as it is by the Avon Gorge) creates complex airflow patterns that make it a particularly interesting and challenging environment for this kind of modelling. Integrating high-resolution, street-level sensor data with these models is a step towards a genuine digital twin of Bristol's urban climate.
Data pipeline and security
The Local Air data pipeline is designed to be robust, automated, and secure. Sensors upload data to a central server via WiFi whenever they are within range of a known network (typically when the scooter is returned to the depot for maintenance). On arrival, the data is automatically decoded, validated, and processed through a cleaning pipeline before being stored in the project database.
All data stored on the sensor itself is encrypted using SPEC encoding, ensuring that the data cannot be accessed even if a sensor is lost or stolen. Raw sensor data is not shared externally; only processed and anonymised data is made available for research use.
Interested in the data? Contact the team to find out more about data access and collaboration opportunities.